
So it is not easy to have a list of OpenStack components/services all in one place. They are everywhere on the web and one can easily get lost. and when you do see a list of services, they are not described in a simple way.
So here is an easy-to-understand list describing the OpenStack components for a quick reference. Whether public clouds or private clouds, OpenStack is everywhere, so you better understand these terms.
What you see in this diagram is the list of core services already described in my blog here which but there are many others, it is an attempt to cover as many OpenStack components and services as possible in this list.
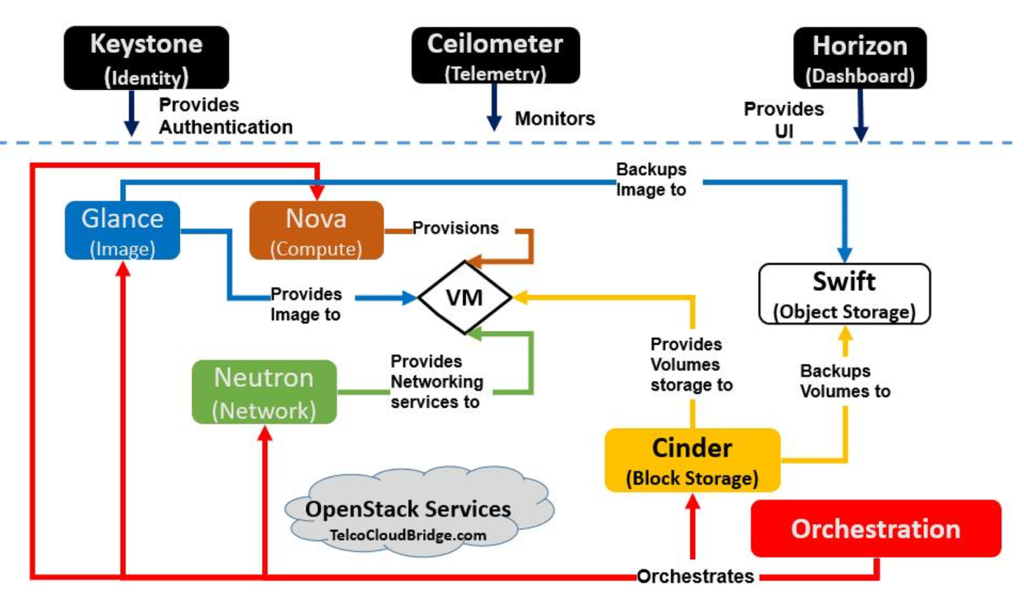
OpenStack Components
COMPUTE:
Nova ( Compute Service)
Nova manages pools of compute resources including VMs, bare metal (through use of ironic), and containers (limited support). The good thing about Nova is that it is hypervisor agnostic so it can use KVM, VMware, LXC, XenServer, etc.
More info: https://docs.openstack.org/nova/latest/
Zun ( Containers service)
As more and more apps are being containerized, cloud users need a more direct way to manage containers. Zun provides a simple way to manage containers through APIs from within OpenStack without having the users understand the complexities of containers. While Nova needs a Nova docker driver for containers management, Zun can do it without depending on the Nova API.
More info: https://docs.openstack.org/zun/latest/
HARDWARE LIFE CYCLE:
Ironic ( Bare Metal Provisioning)
It is a bare metal provisioning service. Although OpenStack generally provisioning Virtual Machines (VMs) but sometimes it is required to provision bare metal. This service allows this through the use of APIs from within OpenStack. Also, it integrates with Nova, enabling Nova to use its services for provisioning bare metals.
More info: https://docs.openstack.org/ironic/latest/
Cyborg ( Accelerator)
The need for Telco workloads requires the use of accelerators ( GPU, FPGA, ASIC, NP, SoCs, NVMe/NOF SSDs, ODP, DPDK/SPDK). Cyborg creates and manages accelerators with either tools or the API directly.
More info: https://wiki.openstack.org/wiki/Cyborg
STORAGE:
Cinder ( Block Storage)
Cinder is an OpenStack Block storage service that allows you to add persistent storage to your virtual machines. It interacts with OpenStack Compute to provide volumes for instances and enables management of volume snapshots and volume types.
More info: https://docs.openstack.org/cinder/latest/
Manila ( Shared File system)
Manila provides shared storage. While Cinder provides it for a single VM, Manila storage can be shared across multiple VMs and instances
More info: https://docs.openstack.org/manila/latest/
Swift (Object Storage)
Have you heard of S3 in AWS which is a cheap way of storing a huge amount of data? Swift provides the same service. It is also called “Object Storage”. It is highly distributed and provides a cost-effective scale-out object storage
More info: https://docs.openstack.org/swift/latest/
Magnum
Magnum takes a step beyond Zun. While Zun launches and manages containers, Magnum makes the more complex orchestration engines like Kubernetes or Docker Swarm, available as a resource in OpenStack. So if the intent is to manage the containers’ engines ( rather than containers), then Magnum is the option.
More info: https://docs.openstack.org/magnum/latest/
NETWORKING
Neutron (OpenStack Networking)
With Neutron, users can create networks and connect devices/servers and services. They can manage IP addresses, create subnets, VLANs, private network, etc. to manage such communication. It provides networking as a service.
More info: https://docs.openstack.org/neutron/latest/
Octavia (Load Balancer)
Octavia provides load balancing services to virtual machines, containers, or bare metal servers. This is done on demand. This on-demand horizontal scaling is a differentiating feature for Octavia compared to other load balancing solutions
More info: https://docs.openstack.org/octavia/latest/
Designate (DNS Service)
Designate brings DNS capabilities to Open stack it provides DNS as a service
More info: https://docs.openstack.org/designate/latest/
SHARED SERVICES
Keystone (Identity Service)
Keystone enables authorization and authentication and thus is an OpenStack identity service. It is used to query which users are authorized to use a cloud service. User name and password credentials are some of the methods that the Keystone unit supports. It is possible to integrate it with systems like LDAP.
More info: https://docs.openstack.org/keystone/latest/
Barbican (Key Management)
This service provides secure secure storage and management of secret data such as passwords, encryption keys, etc
More info: https://docs.openstack.org/barbican/latest/
Glance (Image Service)
Users can discover, register and retrieve virtual machine images using Glance. It offers a REST API that enables you to query virtual machine image metadata and retrieve an actual image. You can keep virtual machine images in a variety of locations, from simple file systems to object-storage systems.
More info: https://docs.openstack.org/glance/latest/
Placement (Placement Service)
In order to help other services effectively manage and allocate their resources, Placement is an OpenStack service that provides an HTTPAPI for tracking cloud resource inventory and usages.
More info: https://docs.openstack.org/placement/latest/
ORCHESTRATION
Heat ( Orchestration)
The deployment of infrastructure, services, and applications can be automated with the help of Heat templates.
More info: https://docs.openstack.org/heat/latest/
Senlin ( Clustering Service)
A new project called Senlin provides a generic clustering service for OpenStack clouds. While Heat can provide such services, but it was decided to offload such function from Heat and provide a dedicated clustering service that can help in auto-scaling.
More info: https://docs.openstack.org/senlin/latest/
Mistral ( Workflow Service)
Mistral provides workflow as a service in OpenStack. Mistral runs a sequence of cloud tasks in a unified manner using the same mechanism.
More info: https://docs.openstack.org/mistral/latest/
WORKLOAD PROVISIONING
Sahara (Big Data Provisioning)
The aim is to bring big data and OpenStack together. Sahara enables creation and management of Hadoop cluster ( or Spark), all from within OpenStack without the need for dealing with another cluster management app
More info: https://docs.openstack.org/sahara/latest/
Trove (Database as a Service)
Trove is a database as a service that runs on OpenStack. It‘s designed to allow users to quickly and easily use the features of a relational database without having to deal with complex administrative tasks. Users and database administrators can provision multiple databases as needed.
More info: https://docs.openstack.org/trove/latest/
APPLICATION LIFECYCLE
Murano ( Application Catalog)
Introducing an application catalog to Openstack, the Murano Project enables application developers and cloud administrators, to publish various cloud-ready applications in a browsable categorized catalog. The actual deployment is done by the orchestration tool such as Heat.
More info: https://docs.openstack.org/murano/latest/
Freezer (Disaster Recovery)
A freezer is a distributed backup and restores as a service platform that enables Disaster as a service in OpenStack. It is designed to be multi-OS ( Linux, windows, etc).
More info: https://docs.openstack.org/freezer/latest/
Masakari ( Instances High Availability Service)
High availability services for clouds are provided by Masakari. If there are failed instances, it automatically recovers them.
More info: https://docs.openstack.org/masakari/latest/
Web Frontend:
Horizon (Dashboard)
OpenStack Dashboard (horizon) provides administrators and end-users with a graphical interface for accessing, provisioning, and automating the deployment of cloud-based services.
More info: https://docs.openstack.org/horizon/latest/
TELEMETRY:
Ceilometer ( Telemetry)
The OpenStack Ceilometer project can be used for monitoring and metering the OpenStack cloud. it is an OpenStack telemetry tool.
More info: https://docs.openstack.org/ceilometer/latest/
So that’s it, let me know in the comments below, what do you want to know more about the OpenStack components.